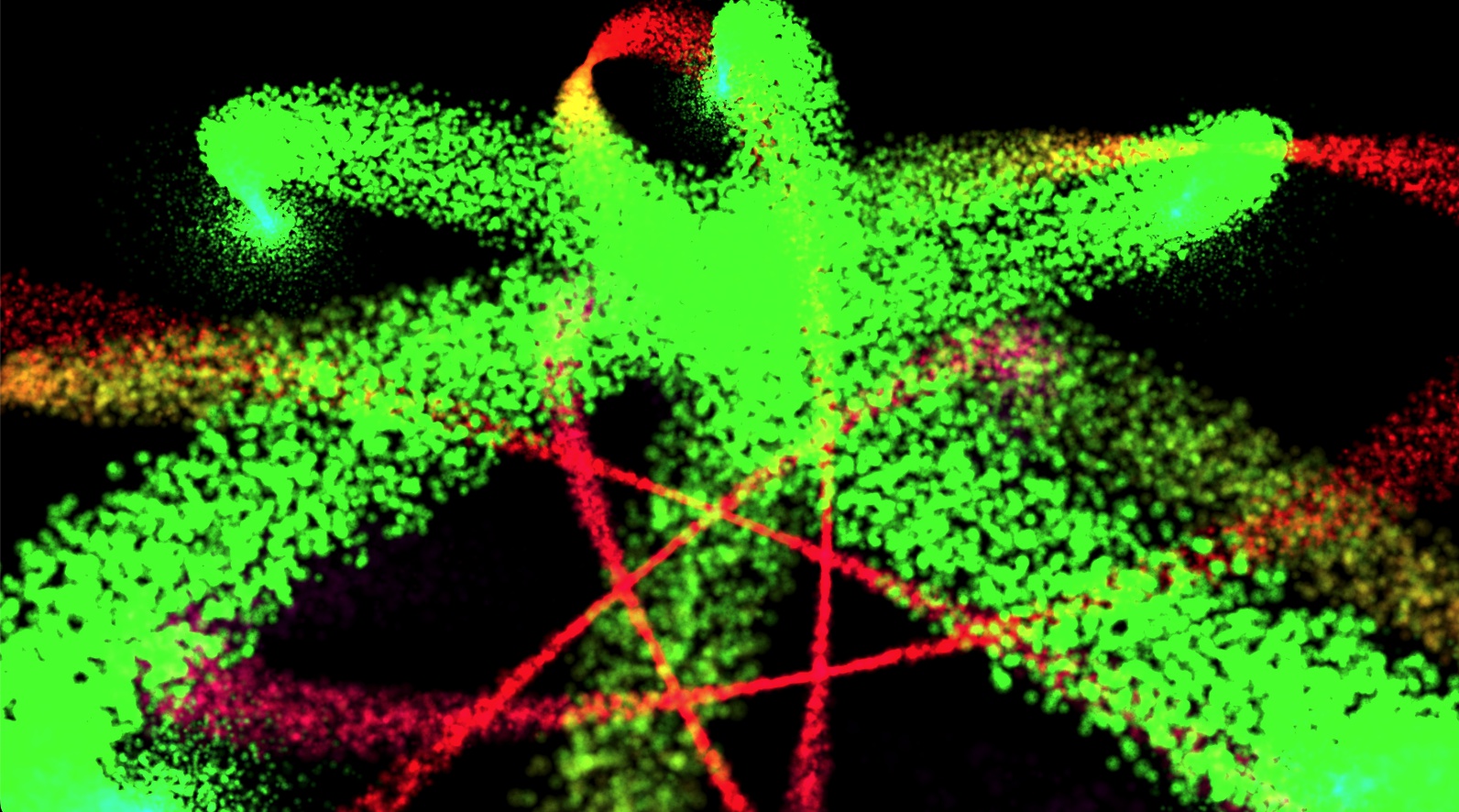
June 25, 2023
02 Hello Compute
Making cross-platform and cross-API GPU particle systems is extremely easy with Tellusim Core SDK. We wanted to make our API very efficient for compute shader dispatching because we have tons of them inside Tellusim Engine. In this example, we will use indirect dispatch, a built-in GPU RadixSort algorithm, and a particle rendering with instancing (for WebGPU compatibility).
A particle system is just an array of objects with the same behavior. Each particle has parameters like position, velocity, lifetime, and rotation. The particle system simulation has two essential parts: particle emission and particle simulation. Particle emission creates new particles with the specified position and parameters. Particle simulation updates particle position according to velocity, and additional external forces can be applied at this step.
We will start with Application, Window, and Device initialization. However, it is crucial to ensure that compute shaders are supported:
/*
*/
int32_t main(int32_t argc, char **argv) {
// create app
App app(argc, argv);
if(!app.create()) return 1;
// create window
Window window(app.getPlatform(), app.getDevice());
if(!window || !window.setSize(app.getWidth(), app.getHeight())) return 1;
if(!window.create("02 Hello Compute") || !window.setHidden(false)) return 1;
window.setKeyboardPressedCallback([&](uint32_t key, uint32_t code) {
if(key == Window::KeyEsc) window.stop();
});
// create device
Device device(window);
if(!device) return 1;
// check compute shader support
if(!device.hasShader(Shader::TypeCompute)) {
TS_LOG(Error, "compute shader is not supported\n");
return 0;
}
We must keep a bunch of structures synchronized between C++ and shader files. So we will declare them in a separate file and include it when required. The maximum number of simulated particles is limited by 1M:
// declarations
#include "main.h"
// parameters
constexpr uint32_t group_size = 128;
constexpr uint32_t max_emitters = 1024;
constexpr uint32_t max_particles = 1024 * 1024;
The Kernel is a class that manages compute shaders. Its configuration is similar to a Pipeline configuration from the previous example, with the exception of the absence of shader stage masks. A simple particle simulation requires kernels for particle initialization, spawning, and update. Additionally, the geometry and indirect dispatch/draw buffers must be updated:
// create init kernel
Kernel init_kernel = device.createKernel().setUniforms(1).setStorages(3, false);
if(!init_kernel.loadShaderGLSL("main.shader", "INIT_SHADER=1; GROUP_SIZE=%uu", group_size)) return 1;
if(!init_kernel.create()) return 1;
// create emitter kernel
Kernel emitter_kernel = device.createKernel().setUniforms(1).setStorages(5, false).setStorageDynamic(0, true);
if(!emitter_kernel.loadShaderGLSL("main.shader", "EMITTER_SHADER=1; GROUP_SIZE=%uu", group_size)) return 1;
if(!emitter_kernel.create()) return 1;
// create dispatch kernel
Kernel dispatch_kernel = device.createKernel().setUniforms(1).setStorages(4, false);
if(!dispatch_kernel.loadShaderGLSL("main.shader", "DISPATCH_SHADER=1; GROUP_SIZE=%uu", group_size)) return 1;
if(!dispatch_kernel.create()) return 1;
// create update kernel
Kernel update_kernel = device.createKernel().setUniforms(1).setStorages(4, false);
if(!update_kernel.loadShaderGLSL("main.shader", "UPDATE_SHADER=1; GROUP_SIZE=%uu", group_size)) return 1;
if(!update_kernel.create()) return 1;
// create geometry kernel
Kernel geometry_kernel = device.createKernel().setUniforms(1).setStorages(4, false);
if(!geometry_kernel.loadShaderGLSL("main.shader", "GEOMETRY_SHADER=1; GROUP_SIZE=%uu", group_size)) return 1;
if(!geometry_kernel.create()) return 1;
All particles must be sorted (back to front) for correct rendering. We will use a built-in RadixSort algorithm with an indirect dispatch and ordering option. Ordering sort mode creates integer indices that map input keys to the sorted state.
// create radix sort
RadixSort radix_sort;
PrefixScan prefix_scan;
if(!radix_sort.create(device, RadixSort::FlagSingle | RadixSort::FlagIndirect | RadixSort::FlagOrder, prefix_scan, max_particles)) return 1;
Now it’s time to create storage buffers that will contain particle parameters:
// create compute state buffer
// contains global particle system state
ComputeState state = {};
Buffer state_buffer = device.createBuffer(Buffer::FlagStorage, &state, sizeof(state));
if(!state_buffer) return 1;
// create emitters state buffer
// contains dynamic emitter parameters
Buffer emitters_buffer = device.createBuffer(Buffer::FlagStorage, sizeof(EmitterState) * max_emitters * group_size);
if(!emitters_buffer) return 1;
// create particles state buffer
// contains per-particle state
Buffer particles_buffer = device.createBuffer(Buffer::FlagStorage, sizeof(ParticleState) * max_particles);
if(!particles_buffer) return 1;
// create particle allocator buffer
// contains new particle indices
Buffer allocator_buffer = device.createBuffer(Buffer::FlagStorage, sizeof(uint32_t) * max_particles);
if(!allocator_buffer) return 1;
// create particle distances buffer
// contains camera to particle distances and order indices
Buffer distances_buffer = device.createBuffer(Buffer::FlagStorage, sizeof(uint32_t) * max_particles * 2);
if(!distances_buffer) return 1;
// create particle vertex buffer
// contains particle position, velocity, and color
Buffer vertex_buffer = device.createBuffer(Buffer::FlagVertex | Buffer::FlagStorage, sizeof(Vertex) * max_particles);
if(!vertex_buffer) return 1;
// create particle indices buffer
const uint16_t indices_data[] = { 0, 1, 2, 2, 3, 0 };
Buffer indices_buffer = device.createBuffer(Buffer::FlagIndex, indices_data, sizeof(indices_data));
if(!indices_buffer) return 1;
// create indirect dispatch buffer
Compute::DispatchIndirect dispatch_data = {};
Buffer dispatch_buffer = device.createBuffer(Buffer::FlagStorage | Buffer::FlagIndirect, &dispatch_data, sizeof(dispatch_data));
if(!dispatch_buffer) return 1;
// create indirect draw buffer
Command::DrawElementsIndirect draw_data = {};
Buffer draw_buffer = device.createBuffer(Buffer::FlagStorage | Buffer::FlagIndirect, &draw_data, sizeof(draw_data));
if(!draw_buffer) return 1;
// create sort parameters buffer
RadixSort::DispatchParameters sort_data = {};
Buffer sort_buffer = device.createBuffer(Buffer::FlagStorage, &sort_data, sizeof(sort_data));
if(!sort_buffer) return 1;
This Compute dispatch will initialize particles. A barrier is required for all buffers that have been updated and will be used in the following stages:
// compute parameters
ComputeParameters compute_parameters = {};
compute_parameters.max_emitters = max_emitters;
compute_parameters.max_particles = max_particles;
compute_parameters.global_gravity = Vector4f(0.0f, 0.0f, -8.0f, 0.0f);
compute_parameters.wind_velocity = Vector4f(0.0f, 0.0f, 4.0f, 0.0f);
compute_parameters.wind_force = 0.2f;
// initialize buffers
{
Compute compute = device.createCompute();
// init kernel
compute.setKernel(init_kernel);
compute.setUniform(0, compute_parameters);
compute.setStorageBuffers(0, { emitters_buffer, particles_buffer, allocator_buffer });
compute.dispatch(max(max_emitters * group_size, max_particles));
compute.barrier({ emitters_buffer, particles_buffer, allocator_buffer });
}
The Compute dispatching is more simple than rendering with Command and Pipeline. The corresponding initialization kernel does nothing except for storage buffer writes. The allocator buffer contains indices for new particles. The last element contains the first particle index for better memory access. GLSL will be automatically converted to the target platform shader language, including Cuda and Hip compute:
layout(local_size_x = GROUP_SIZE) in;
layout(std140, binding = 0) uniform ComputeParametersBuffer { ComputeParameters compute; };
layout(std430, binding = 1) writeonly buffer EmitterStateBuffer { EmitterState emitters_buffer[]; };
layout(std430, binding = 2) writeonly buffer ParticleStateBuffer { ParticleState particles_buffer[]; };
layout(std430, binding = 3) writeonly buffer IndicesBuffer { uint allocator_buffer[]; };
/*
*/
void main() {
uint global_id = gl_GlobalInvocationID.x;
// initialize emitters
[[branch]] if(global_id < compute.max_emitters * GROUP_SIZE) {
emitters_buffer[global_id].position = vec4(0.0f);
emitters_buffer[global_id].seed = ivec2(global_id);
emitters_buffer[global_id].spawn = 0.0f;
}
// initialize particles
[[branch]] if(global_id < compute.max_particles) {
particles_buffer[global_id].position = vec4(1e16f);
particles_buffer[global_id].velocity = vec4(0.0f);
particles_buffer[global_id].radius = 0.0f;
particles_buffer[global_id].angle = 0.0f;
particles_buffer[global_id].life = 0.0f;
}
// initialize particle indices
[[branch]] if(global_id < compute.max_particles) {
allocator_buffer[global_id] = compute.max_particles - global_id - 1u;
}
}
Now everything is ready for particle system simulation that must be executed per frame:
// simulate particles
{
Compute compute = device.createCompute();
// compute parameters
compute_parameters.camera = Matrix4x3f::rotateZ(-time * 8.0f) * Vector4f(32.0f, 0.0f, 32.0f, 0.0f);
compute_parameters.num_emitters = emitters.size();
compute_parameters.ifps = ifps;
// emitter kernel
compute.setKernel(emitter_kernel);
compute.setUniform(0, compute_parameters);
compute.setStorageData(0, emitters.get(), emitters.bytes());
compute.setStorageBuffers(1, { state_buffer, emitters_buffer, particles_buffer, allocator_buffer });
compute.dispatch(emitters.size() * group_size);
compute.barrier({ state_buffer, emitters_buffer, particles_buffer, allocator_buffer });
// dispatch kernel
compute.setKernel(dispatch_kernel);
compute.setStorageBuffers(0, { state_buffer, dispatch_buffer, draw_buffer, sort_buffer });
compute.dispatch(1);
compute.barrier({ dispatch_buffer, draw_buffer, sort_buffer });
// update kernel
compute.setKernel(update_kernel);
compute.setUniform(0, compute_parameters);
compute.setStorageBuffers(0, { state_buffer, particles_buffer, allocator_buffer, distances_buffer });
compute.setIndirectBuffer(dispatch_buffer);
compute.dispatchIndirect();
compute.barrier({ state_buffer, particles_buffer, allocator_buffer, distances_buffer });
// sort particles
if(!radix_sort.dispatchIndirect(compute, distances_buffer, sort_buffer, 0, RadixSort::FlagOrder)) return false;
// geometry kernel
compute.setKernel(geometry_kernel);
compute.setUniform(0, compute_parameters);
compute.setStorageBuffers(0, { state_buffer, particles_buffer, distances_buffer, vertex_buffer });
compute.setIndirectBuffer(dispatch_buffer);
compute.dispatchIndirect();
}
As a result, we have particle positions, velocities, and colors in the vertex buffer and rendering parameters in the indirect buffer. The only rule you should follow is to have required write-read barriers between stages. Our debug run-time will tell you all errors about invalid kernel arguments if there are any. Let’s render our particle system:
// window target
target.begin();
{
// create command list
Command command = device.createCommand(target);
// set common parameters
CommonParameters common_parameters;
common_parameters.projection = Matrix4x4f::perspective(60.0f, (float32_t)window.getWidth() / window.getHeight(), 0.1f, 1000.0f);
common_parameters.modelview = Matrix4x4f::lookAt(compute_parameters.camera.xyz, Vector3f::zero, Vector3f(0.0f, 0.0f, 1.0f));
if(target.isFlipped()) common_parameters.projection = Matrix4x4f::scale(1.0f, -1.0f, 1.0f) * common_parameters.projection;
// set pipeline
command.setPipeline(pipeline);
command.setSampler(0, sampler);
command.setTexture(0, texture);
command.setUniform(0, common_parameters);
command.setVertexBuffer(0, vertex_buffer);
command.setIndexBuffer(FormatRu16, indices_buffer);
// draw particles
command.setIndirectBuffer(draw_buffer);
command.drawElementsIndirect(1);
}
target.end();
This sample runs on Android, iOS, WebGPU, Windows, Linux, and macOS platforms with excellent performance and does not require any source code modification. The left image is a link to the WebGPU application that can run in your browser: