June 19, 2022
Intel Arc 370M analysis
Intel Arc GPU was announced a while ago, but we did not have an opportunity to analyze its performance until now. Because VK performance is lower on Intel GPUs we will use D3D12 API for tests. The driver version for Arc GPU is 30.0.101.1736, while the Xe GPU has a more recent driver version 30.0.101.3109. The main focus is raw Arc GPU performance in comparison with other GPUs. We can easily extrapolate the numbers to get the approximate performance of the upcoming Intel Arc 770M, which has 4x cores and faster memory. So just multiple (divide) results by 4.
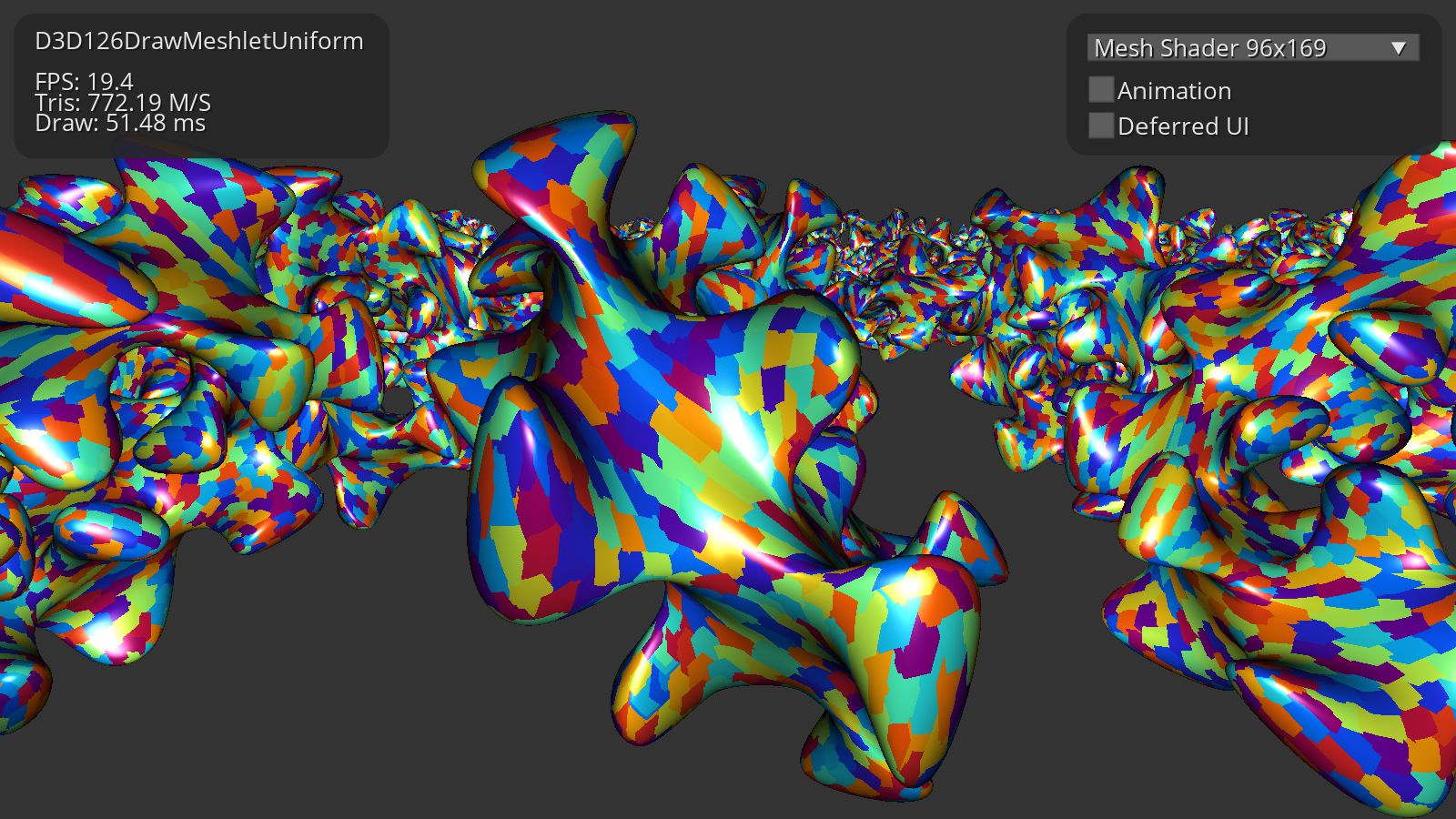
We will see how the new GPU handles triangles and batches in the first test. This is the same test we used before. The Meshlet size is 69/169. The test is rendering 262K Meshlets. The total amount of geometry is 20M vertices and 40M triangles per frame.
| Single DIP | Mesh Indexing | MDI/ICB | Mesh Shader | Compute Shader | |
|---|---|---|---|---|---|
| Intel Arc A370M | 3.2B | 1.0B | 2.9B | 770M | 3.0B |
| Intel Iris Xe (12th) | 1.6B | 450M | 1.6B | 2.9B | |
| Intel Iris Xe (11th) | 1.2B | 370M | 400B | 2.3B | |
| Apple M1 Max | 8.3B | 3.5B | 2.2B | 12.3B | |
| Apple M1 | 1.4B | 648M | 1.0B | 2.7B | |
| GeForce 2080 Ti | 15.5B | 5.2B | 17.5B | 14.3B | 17.8B |
| GeForce 1060 | 3.8B | 1.2B | 4.0B | 4.5B | |
| Radeon 6700 XT | 14.2B | 6.2B | 6.3B | 4.6B | 17.0B |
| Radeon 5600 M | 5.0B | 2.4B | 2.1B | 7.4B | |
| Radeon 4800H | 1.2B | 530M | 1.2B | 1.5B | |
| Adreno 730 | 890M | 287M | 120M | 423M |
- Unit is Billion or Million triangles per second.
- Single DIP is drawing 81 instances with u32 indices without going to Meshlet level.
- Mesh Indexing is a Mesh Shader emulation trick from this post.
- MDI/ICB is Multi Draw Indirect or Indirect Command Buffer.
- Mesh Shader is using Mesh Shaders rendering mode.
- Compute Shader is using Compute Shader rasterization.
Intel Arc 370M provides 2x better performance in triangle rasterization throughput. But unfortunately, there is no increase in Compute Shader calculations, and Arc GPU shows almost the same result as Xe GPU. The 12th generation of Xe GPU also has some benefits from increased DDR5 memory bandwidth compared to the 11th generation that uses DDR4. With the new Xe generation, there is also a huge 4x performance boost in MDI performance.
Mesh Shader rendering performance is not good. GPU is losing 4x of its theoretical triangle throughput. The Mesh Shader emulation trick is better than Mesh Shader on Intel Arc as well.

The second test is Ray Tracing test with CS and API (HW) rendering modes.
| CS Static | API Static | CS Dynamic Fast | API Dynamic Fast | CS Dynamic Full | API Dynamic Full | |
|---|---|---|---|---|---|---|
| Intel Arc A370M | 15.0 FPS | 142 FPS | 23.8 FPS (8ms/15ms) | 62.3 FPS (8ms/3ms) | 12.0 FPS (53ms/12ms) | 20.8 FPS (40ms/3ms) |
| Intel Iris Xe (12th) | 11.5 FPS | 12.5 FPS (14ms/56ms) | 7.4 FPS (76ms/32ms) | |||
| Intel Iris Xe (11th) | 10.1 FPS | 8.8 FPS (17ms/60 ms) | 5.4 FPS (101ms/50ms) | |||
| Apple M1 Max | 68.4 FPS | 63.9 FPS | 34.8 FPS | 28.7 FPS | 28.5 FPS | 2.7 FPS |
| Apple M1 | 16.5 FPS | 16.5 FPS | 11.3 FPS | 14.3 FPS | 7.3 FPS | 1.7 FPS |
| GeForce 2080 Ti | 74.2 FPS | 803 FPS | 74.5 FPS (2ms/8ms) | 353 FPS (1.1ms/0.6ms) | 58.1 FPS (8.8ms/5ms) | 61.2 FPS (15ms/0.5ms) |
| GeForce 1060 | 18.0 FPS | 16.8 FPS (10ms/35ms) | 13.7 FPS (32ms/26ms) | |||
| Radeon 6700 XT | 134 FPS | 368 FPS | 62.7 FPS (3ms/10ms) | 155 FPS (5ms/1ms) | 50.4 FPS (9ms/8ms) | 22 FPS (44ms/1ms) |
| Radeon 5600 M | 73.3 FPS | 35.2 FPS (6ms/16ms) | 25.7 FPS (19ms/13ms) | |||
| Radeon 4800H | 11.7 FPS | 7.5 FPS (35ms/66ms) | 5.2 FPS (109ms/52ms) |
- CS Static is Compute Shader ray tracing from our post (40M triangles total).
- CS Dynamic Fast is Compute Shader ray tracing from this post (4.2M triangles and 2.9M vertices total).
- CS Dynamic Full the same as CS Dynamic Fast but with full BLAS rebuild instead of fast BVH update.
- API Static, API Dynamic Fast, and API Dynamic Full uses API-provided ray tracing.
- Timings show BLAS update / Scene tracing times.
In these tests, the new Arc architecture demonstrates much better compute performance on loads with big threads divergence. HW ray tracing rate is great in comparison with compute shader implementation. RT performance of Arc 770M should be better than RT performance of AMD Radeon GPUs based on results extrapolation.
Let’s see how much memory we need for BLAS and Scratch buffers:
| Static BLAS | Static Scratch | Dynamic BLAS | Dynamic Scratch | |
|---|---|---|---|---|
| Intel Arc A370M | 66 MB | 23 MB | 642 MB | 280 MB |
| Apple M1 | 82 MB | 88 MB | 355 MB | 382 MB |
| GeForce 2080 Ti | 33 MB | 10 MB | 255 MB | 16 MB |
| Radeon 6700 XT | 77 MB | 105 MB | 656 MB | 887 MB |


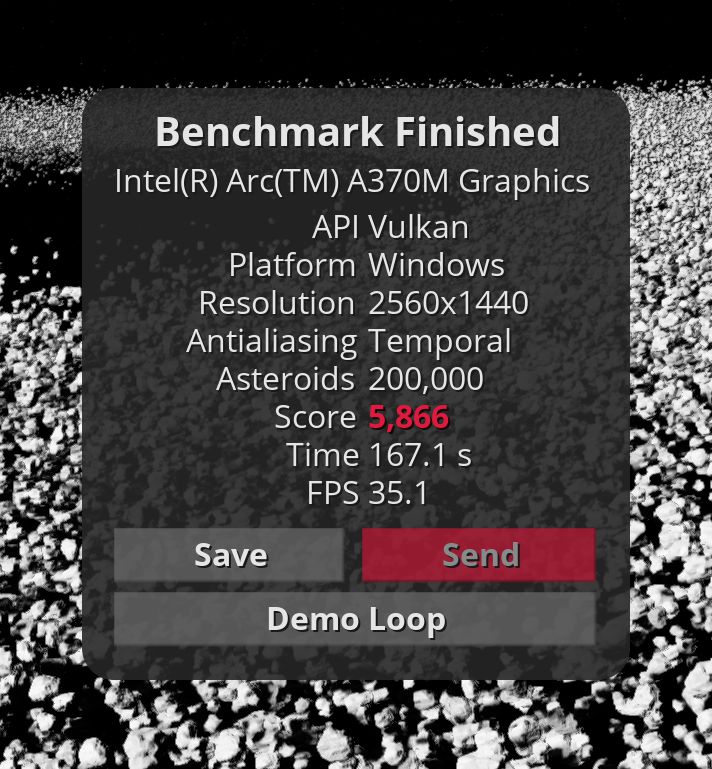
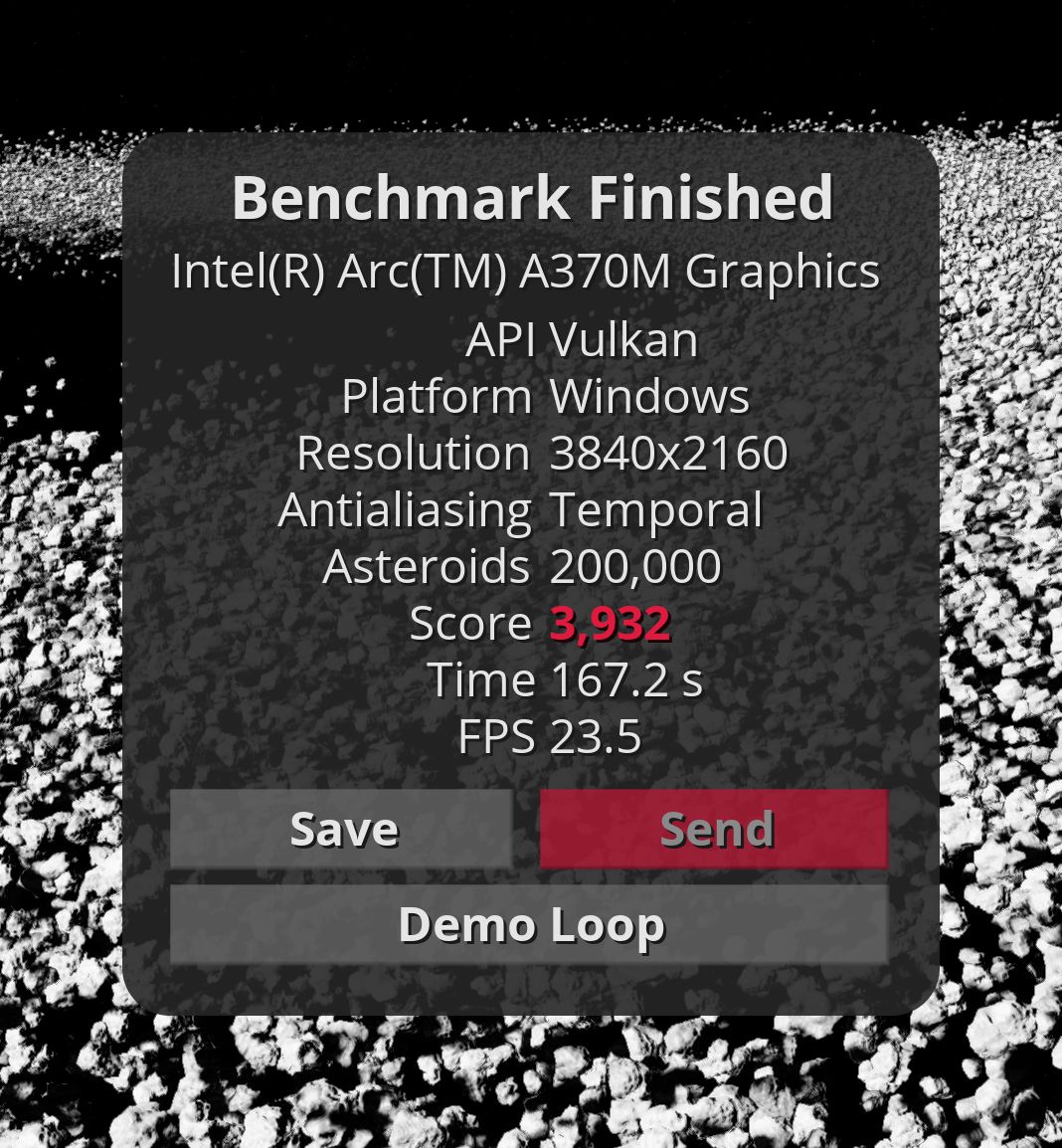
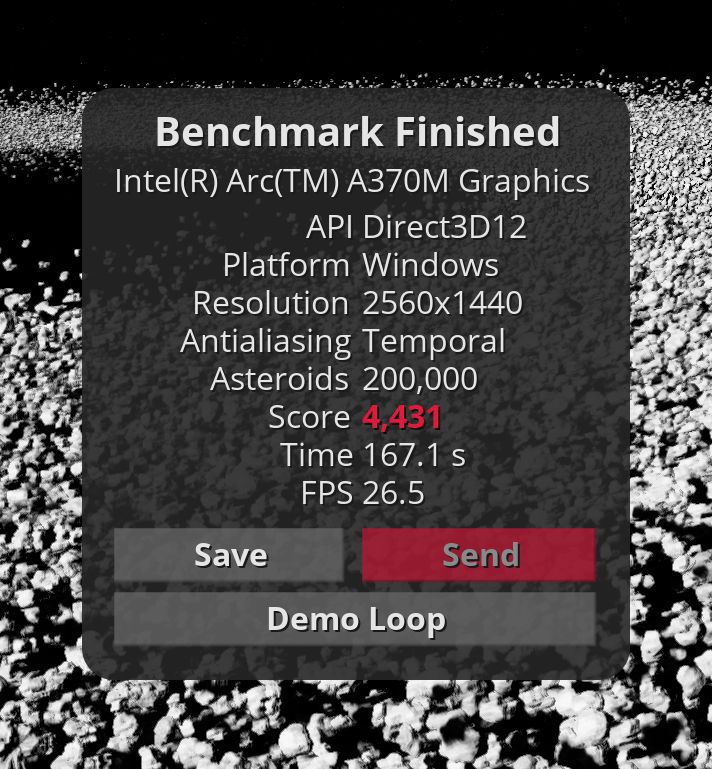
The numbers from the new Intel GPU look promising. But GravityMark benchmark crashes on D3D12 (Raster and RT) API, where Arc should demonstrate its potential. But in fact, we have results that are worse than the Intel Xe generation and even worse than Apple A15. Hopefully, it will be improved with new driver updates because, at this moment, Intel Xe is faster than Intel Arc.
Intel Arc and Intel Xe don’t have a big difference in Compute performance. So probably driver can use both GPUs for rendering. Like emulating multiple compute queues that work on different GPUs. If this is true, Intel’s driver team has a lot of work to do.
Update: ExecuteIndirect() with GPU-specified count is crashing D3D12 driver. A CPU-GPU synchronization workaround (count parameter fetch) allows running GravityMark on D3D12. But unfortunately, this workaround is not helping Vulkan to be as fast as D3D12.
Update 2: Thanks to Intel developer relations, a simple engine optimization (flexible subgroup size) gives >200% better performance on Intel Arc GPU in Vulkan.