
September 9, 2021
MultiDrawIndirect and Metal
The most significant omission of Apple Metal API is an absence of MultiDrawIndirect functionality. MDI is the most compatible way of rendering for GPU-driven technology. There are several ways how we can emulate MDI on macOS and iOS.
The simplest way is a loop of drawIndexedPrimitives() commands with different offsets to indirect buffer. MultiDrawIndirectCount will require a CPU-GPU synchronization to get the Count value from GPU memory. Maybe it is not a very optimal way, but it is working and even can outperform a single MDI call on some hardware because of insufficient driver optimizations.
for(uint32_t i = 0; i < num_draws; i++) {
[encoder drawIndexedPrimitives:... indirectBufferOffset:offset];
offset += stride;
}
The official Metal way is to use Indirect Command Buffer and encode rendering commands on CPU or GPU. All textures and samples must be passed as Argument buffer parameters even if they are not changing during rendering. Metal shading language has a built-in draw_indexed_primitives() function that 100% corresponds to their Metal API analog. That sounds good except minor limitation of 16384 drawing commands.
In theory a single call to executeCommandsInBuffer() must easily outperform the loop of drawIndexedPrimitives(). But let's perform some tests for that. We will use the same applications we used in our Mesh Shader performance comparison.
| Loop | ICB | VS | |
|---|---|---|---|
| Apple M1 4/2 | 20 M | 48 M | |
| Apple M1 64/84 | 698 M | 794 M | |
| Apple M1 64/126 | 740 M | 840 M | |
| Apple M1 96/169 | 1.22 B | 933 M | |
| Apple M1 128/212 | 1.49 B | 1.05 B | |
| Apple M1 32-bit indices | 1.36 B | ||
| Radeon Vega 56 4/2 | 24 M | 16 M | |
| Radeon Vega 56 64/84 | 1.13 B | 647 M | |
| Radeon Vega 56 64/126 | 1.20 B | 687 M | |
| Radeon Vega 56 96/169 | 1.84 B | 1.05 B | |
| Radeon Vega 56 128/212 | 2.54 B | 1.44 B | |
| Radeon Vega 56 32-bit indices | 3.9 B |
- The ICB performs better than the loop when the number of primitives per draw call is small on Apple GPU. But ICB is 1.5 times slower when DIPs contain more than 200 primitives. And this is a kind of weird behavior of ICB.
- The ICB is always almost two times slower than the loop of indirect commands on AMD GPU. But the exciting thing is that the power-hungry AMD Radeon Vega 56 is running with approximately the same performance as the integrated Apple M1.
But how about running tests with the same HW under Direct3D12 and Vulkan:
| Metal Loop | Metal ICB | D3D12 MDI | VK MDI | |
|---|---|---|---|---|
| Radeon Vega 56 4/2 | 24 M | 16 M | 34 M | 34 M |
| Radeon Vega 56 64/84 | 1.13 B | 647 M | 1.34 B | 1.33 B |
| Radeon Vega 56 64/126 | 1.20 B | 687 M | 1.41 B | 1.40 B |
| Radeon Vega 56 96/169 | 1.84 B | 1.05 B | 2.13 B | 2.11 B |
| Radeon Vega 56 128/212 | 2.54 B | 1.44 B | 2.91 B | 2.84 B |
- The loop of indirect commands is almost as fast as a single API MDI call. But the cost of performance is a huge CPU load. ICB and MDI solutions are not loading the CPU at all.
- All AMD GPUs have native MDI functionality available even for D3D11, but not for Metal. It's understandable that AMD GPU is not the main target for Apple.
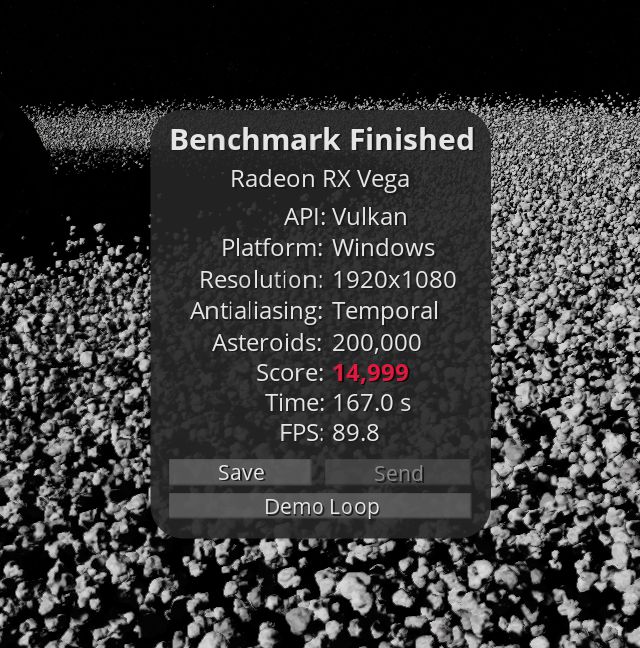
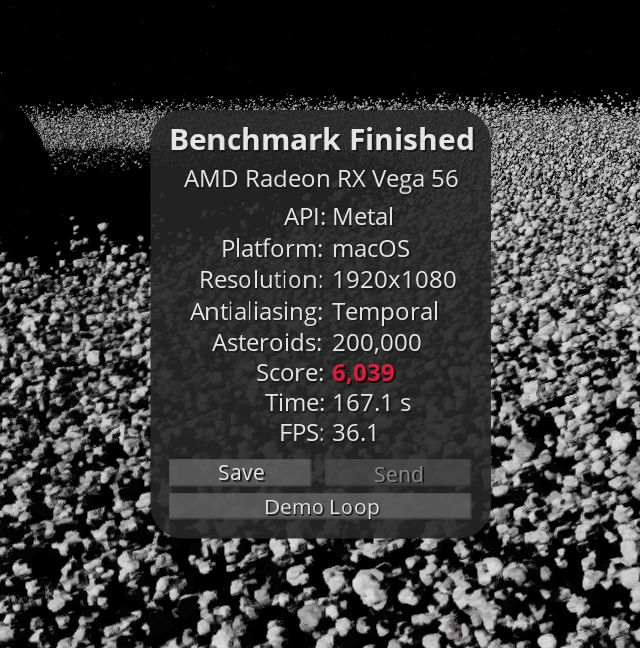
The current version of the GravityMark benchmark uses a loop approach for rendering for Metal. This dramatically reduces the performance of the same AMD GPU:
ICB is not a widely used functionality that is very difficult to debug. Metal shader validation is still not compatible with ICB. Application is crashing with:
-[MTLGPUDebugDevice newIndirectCommandBufferWithDescriptor:maxCommandCount:options:]:1036: failed assertion `Indirect Command Buffers are not currently supported with Shader Validation'
Fortunately, there is MTL_SHADER_VALIDATION_GPUOPT_ENABLE_INDIRECT_COMMAND_BUFFERS parameter that can enable ICB validation. But trivial ICB shaders can cause a non-trivial error:
Compiler encountered an internal error
It's possible to simplify a trivial ICB shader so it will pass the compilation stage. Then MTLArgumentBuffer will remind that he also has his own debugger:
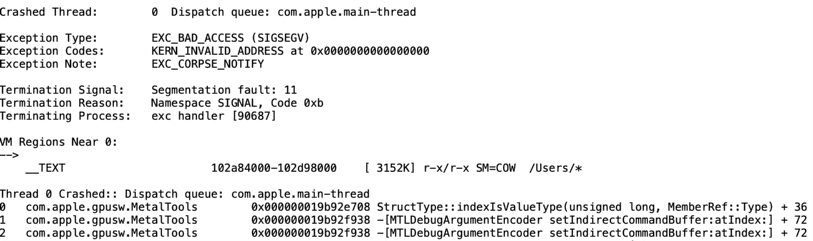
Okay, there is no debugging available for ICB now. Let's try without it. The good thing is that macOS usually is not hanging for more than 20 seconds in the case of error. And more often, a nice Magenta screen is telling that it's something is going wrong:

As a result, we have an internal ICB version of GravityMark which demonstrates that:
- GPU-CPU synchronization is required because the indirect version of executeCommandsInBuffer() causes Magenta screen on M1.
- 16384 ICB length limit is too low for all asteroids, so we should repeat the indirect version of the executeCommandsInBuffer() command a couple of times.
- AMD is 18% slower with ICB than with the Loop. The only bonus is that the CPU is free. Native Windows or Linux on Mac will give 3x boost for graphics.
- M1 is 39% faster with ICB than with the Loop. It should be even better without synchronization. But even with this limitation, M1 outperforms the best integrated GPUs.
- A14 is 44% faster with ICB than with the Loop. It is crashing at the last take with a 3600 score result instead of 2536.
- It is a bad time to buy Mac with AMD GPU for macOS.